/ 2019-09-09
AI赋能安全运维工作初探
安全与机器学习
目前在安全领域已经有很多方向尝试借助机器学习来解决问题,如恶意软件检测、违规图片识别,垃圾邮件识别,UEBA等。
机器学习在垃圾邮件、风控系统和违禁图片识别方向是效果比较显著的,比如对违禁图片进行打标,通过机器学习进行自动分类。
现阶段,大部分机器学习仅仅是融入到各种安全产品中,而在基础安全领域并没有得到很好的利用。一方面是机器学习本身有一定的成本,在日常运维中使用有一定的门槛;另一方面在基础安全领域的机器学习的效果受制于样本的限制,比如在Webshell的检测中,我们发现现有的Webshell样本是远远不够的,有些时候我们会在实践过程中发现,算法的准确性还不如一些简单的规则。
实际上,并不是所有的场景都适合现阶段的机器学习落地,这里我们先来关注一些适合机器学习的场景,比如大量日志数据的处理和分析。
前面的分析我们已经知道,面对大量日志的分析和处理,我们之前使用的初级工具(shell命令、python脚本等)和中级工具(ES搜索、HiveSQL等)等都已经满足不了我们的需求了,这时候我们就需要使用机器学习这个高级工具了。
通过日志分析发现异常用户
背景介绍
日志分析和审计在安全运维工作中经常遇到,这里我们考虑一个很简单的日志审计需求:有一个业务,提供了敏感接口的访问日志,需要安全工程师发现哪些人有问题。
针对这类问题,目前比较常见的分析方式主要是基于统计方式,最常见的就是频次统计,比如每个员工的访问阈值是100次/天,当超过了100次我们就报警。这类的分析统计实现是比较简单的,通过时间窗口来实现。
这里,为了展示方便,我选取了一个访问量小的业务,用其中一个功能的访问日志做说明。
简单分析
日志记录的主要信息是:谁在什么时间在什么地点 对谁 干了什么事情?
这里面,每一个维度可以单独分析,同时也可以联合分析,很多时候结果完全依赖于运营人员的经验或者是系统的规则。
通常情况下,我们分析的维度包括:
频率:单个用户在一段时间范围内的行为超过了某个阈值;
时域:在特定的时间做这件事情,如在凌晨3点,下载了3份文件;
地点:通常情况是IP,这里可以和威胁情报做Join,也可以根据业务做分析,比如是员工通过一台美国的服务器访问了xx系统;
这些条件还可以组合,综合一些规则条件来处理。当然,再复杂一点就是一个简单的日志行为分析系统了。
我们考虑一些场景,如果是一些应急的分析需求,日志量有不小,我们怎么来快速进行分析呢?或者是已经有很多日志数据了,因为数据量太大而没有利用起来,我们是否能挖掘其中的价值呢?
这里我们尝试使用机器学习的算法来进行一些分析。
具体实例——发现异常用户
很多时候,我们的需求是发现异常用户行为,所以需要有工具帮助我们快速提取异常的用户行为。有过日志分析经验的同学应该会有这样的经验:通常情况下,大部分的用户基本都是正常请求;有部分用户的请求是异常;但是异常的情况之间往往有很大的差异。简单来说就是正常的人都差不多,奇葩的人可能有各种奇葩。那么,我们怎么去提取这些“奇葩”呢?
最理想的情况就是通过机器学习的算法,直接区分出正常和异常的用户。正如我们前面提到的,异常的情况可能是多种多样,所以这里我们不能简单的进行二分类,而是考虑使用聚类算法,先进行分类,再针对各类的用户进行针对性的分析,这里我们尝试使用K-Means算法。
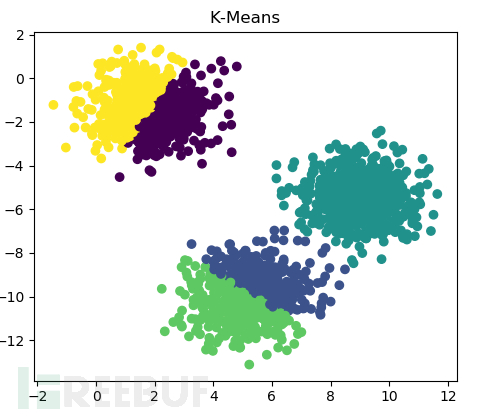
上图就是通过K-Means算法分簇效果展示,通过图表相信大家比较容易理解。
很多时候一开始分析日志时,我们并不清楚正常访问和异常访问具体的特征和区别,所以这里使用 K-Means算法,K-Means本身是无监督学习算法,所以我们在使用时并不需要花费大量的时间来搜集样本,并进行模型训练(终于不用像识别图片验证码那样整理一大堆的样本文件了)。
另外一个很重要的原因就是K-Means算法非常容易实现,上手也比较容易,简单的来说就是先根据请求的特性进行分类,然后我们去掉正常的请求(通常情况下数量最多的一簇),针对其他簇(异常)进行深入分析。
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
有关“簇”和“质心”参考下图:
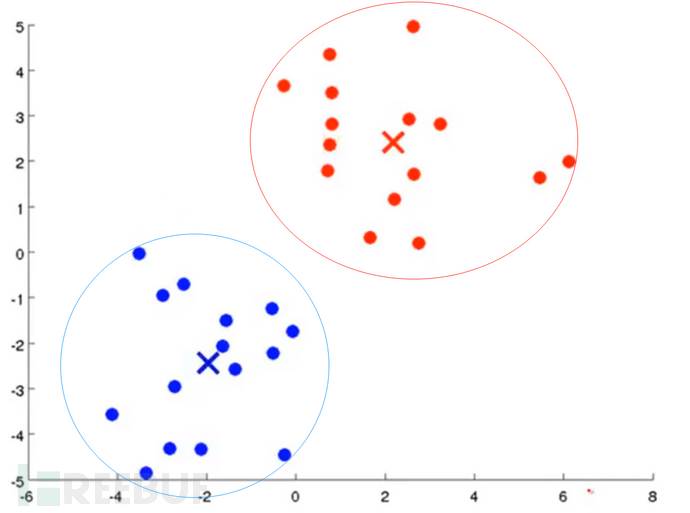
这里具体的原理我们暂时不做解释,感兴趣的同学可以通过搜索引擎自行了解。
算法实践
为了大家方便了解,我们提取了部分数据做一个简单的分析演示。
这是某个系统,敏感接口的访问日志(IP地址和页面信息已经做了脱敏处理),我们现在简单的从用户的访问频次来进行分析。
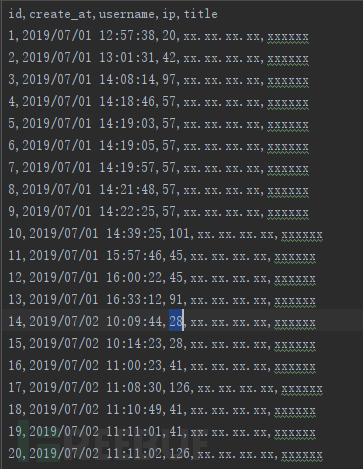
我们现在主要目的是区分正常用户和异常用户,这里我们并没有之前的用户数据参考,所以选择非监督学习的K-Means算法。
提取特征
首先是提取特征,为了方便演示,我们这里仅使用单个维度特征(用户每天的访问次数):
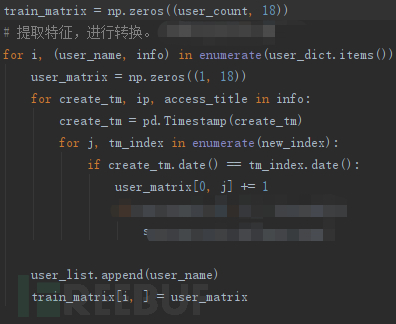
我们可以先直接通过折线图看一下各个用户的访问情况:
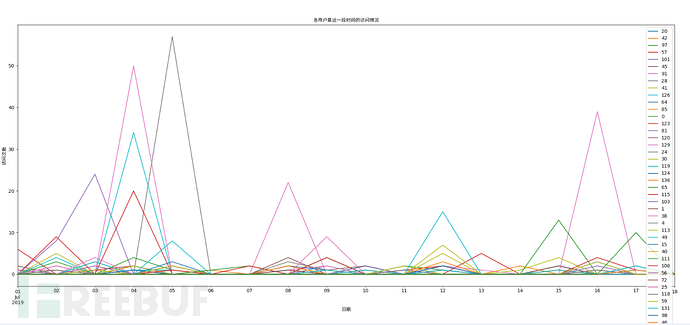
通过访问情况图表,我们只能比较直观的观察到一些比较明显的数量较多的情况。
因为这个特征本身是数字特征,所以可以直接作为算法的特征,又是单一维度,也省掉了特征转换的一个过程。
提取完特征,我们借助K-Means算法来进行分类,算法会根据业务情况将数据分为几类,到底分为几类需要用户指定,那到底几类比较合理呢?我们可以通过一些方法帮我们决定。
比较直观和常用的方法时肘部法则(Elbow Method),我们来看一下运行的结果:
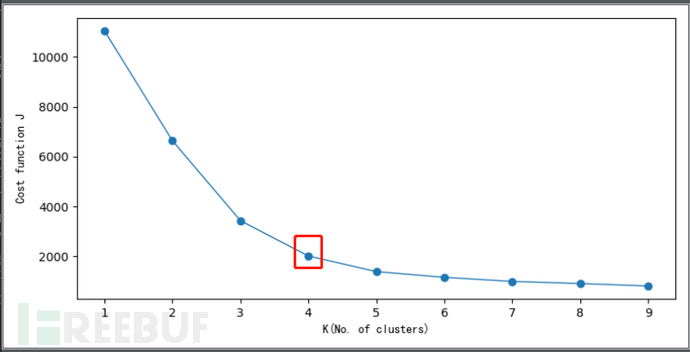
我们可以看到,通过画K与cost function的关系曲线图,如左图所示,肘部的值(cost function开始时下降很快,在肘部开始平缓)做为K值,K=4。
PS:并不是所有的问题都可以通过画肘部图来解决,这里使用肘部图是为了方便让大家观察。
这里,我们直接调用sklearn中的KMeans算法:
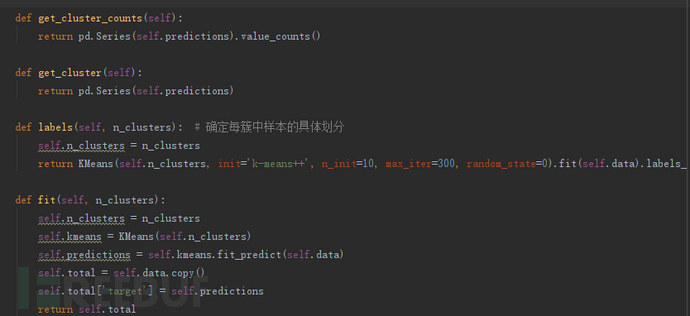
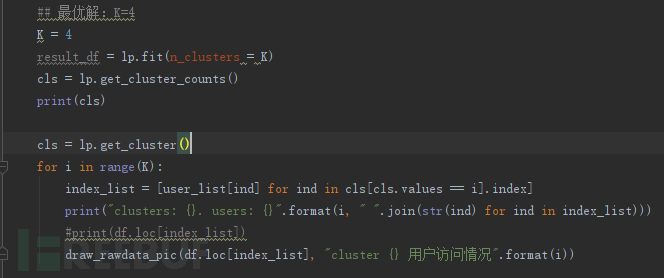
分类完成,发现异常情况
通过K-Means分类,我们可以发现这四类的情况
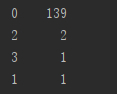
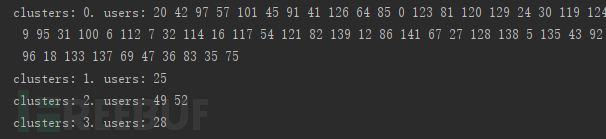
0簇的用户最多,139个,根据我们的经验判断这139个用户是正常的。所以我们的重点可以放在后面3个簇中,即关注用户25,28,49,52的行为。
这里我们观察一下这4个异常用户的访问情况,我们可以看到这几个异常用户确实是可疑用户,和我们之前通过阈值分析结果匹配,并且还有些行为特定,如突然某一天的访问量都突然增多。
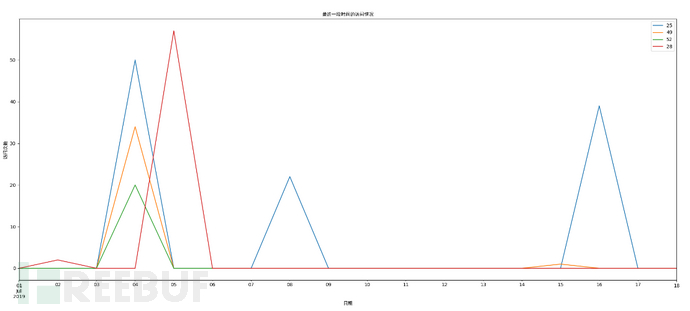
说明:
K-Means很多时候只能帮助我们进行分簇,并不能直接解决问题,分类之后的工作还是需要安全工程师人工进行分析。
如果面对海量的用户访问数据,通常情况下正常用户的访问占大部分(特别是内部系统),所以使用算法能够帮助我们排除大量正常的数据,让安全工程师更专注于异常的数据分析,可以大大的提高我们的分析效率。
后续
在一些UBA/UEBA的产品中,也是使用了K-Means算法或者其他的聚类算法。当然,在实际情况中远远不止这些工作,从特征提取到模型训练,交叉对比等机器学习有一套完整的工程化流程。
同时,我们也需要注意,并非所有的异常都是有安全问题的,这里就需要安全运营通过对业务的敏感性,以及和业务对接的方式去分析和排查。
*本文作者:wangyiyunyidun,转转载须注明来自FreeBuf.COM

(2)
分享至